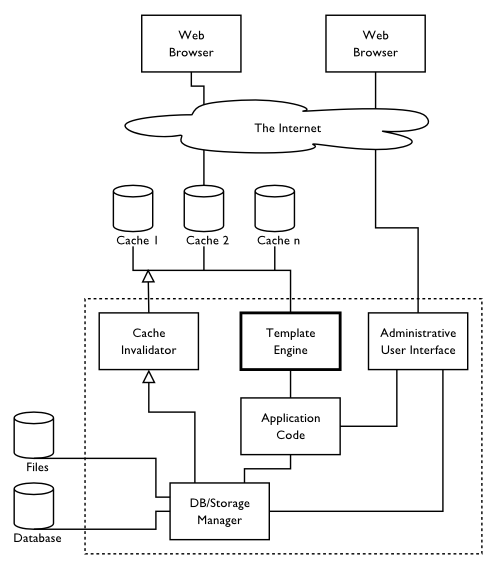
Figure 1: System outline
Helsinki University of Technology
Department of Computer
Science and Engineering
Laboratory of Information Processing
Science
2004-04-03
To enhance the maintainability of Web sites, methods for separating the style from the structure and methods for separating site chrome (non-content such as navigation) from content proper are sought. Separating the style from the structure is addressed by CSS. Separating the chrome from the content is commonly addressed by using templates.
Usually the template is treated as a string, some substrings of which are passed through literally, while others are interpreted as template directives which are replaced with the results of the interpretation. Since character-level (or byte-level) templating does not enforce the grammar of the markup language being produced, the output usually contains syntax errors.
We present a template engine that operates on XML document trees instead of strings. That is, the syntax tree that our Template Engine acts upon is the document tree of the target language augmented with nodes for templating. This approach allows us to avoid many of the pitfalls of string-level templating. With string-level templating, even if a syntax tree is constructed, the parts of the template that are written in the target language are treated as string literals in the syntax tree of the template language. Unlike XSLT, our template language is designed for combining pieces of XHTML. Our template language, by design, is not a general-purpose XML transformation language.
The tree representation used is DOM Level 2 Core. The choice of framework, the correctness of the implementation, problems with the DOM and the relationship with other templating methods are discussed. The implementation is found to achieve low-level (XML) correctness but not guaranteed high-level (XHTML) correctness. The problems with the DOM are found to be manageable. The suitability of the XML syntax as a human-written syntax for purposes other than marking up text is questioned.
Our team set out to write a multi-site content management system for Web publishing as our Project in Software Technology. The system is intended to be hosted by a service provider who creates virtual hosts for site owners. The site owners themselves are not expected to be experts in running a Web site.
The main components of the system are
In this paper, we present the Template Engine. (Lacking a proper name, we refer to our template engine as the Template Engine in this paper.) The other components are presented in [DBS], [WebUI], [App] and [Cache]. Figure 1 shows the Template Engine in the context of the system. The Template Engine interacts with the caches placed in front of the system and with the application code, which acts as the data source for the Template Engine.
The system is designed with three groups of users in mind: site owners who enter content into the system, site designers who take care of the visual design and site navigation and administrators working on behalf of the service provider.
The second group, the site designers, is the group of users that works with the template language which is implemented in the Template Engine. The template writers are expected to be familiar with HTML and CSS but are not expected to have programming background. Also, the designers and the site owners are not allowed to modify the system itself as the site owners must not be able to interfere with each other’s sites. Even though the service provider could modify the system itself, that power is not given to the site designers.
The Template Engine we present is designed to allow a Web page to be assembled from multiple XHTML pieces using a concise language designed specifically for that purpose. Our solution is based on manipulating XML document trees, although usually templating is done on the string level. Using a document tree representation guarantees the absence of XML well-formedness errors and similar low-level HTML errors.
We decided to implement the system in Java, because all the team members had programmed in Java before and XML tools are readily available for Java.
The appearance of Web sites changes over time. Usually, it is desirable to apply the new appearance to the old content as well, in order to maintain the unified feel of the site. In addition to the content itself, Web pages consist of navigational parts and parts that establish the identity of the site. For maintainability, methods for modularizing these aspects of Web pages are required.
When the graphic appearance of a textual document has been designed sensibly, the stylistic properties of the text indicate common structures (paragraphs, headings, etc.) even if the author of the document doesn’t realize this. The same content can be presented in another way if these structures are encoded explicitly and the presentation of the structures is encoded separately.
Once the structure has been described using HTML [HTML4], the presentation can be suggested using the CSS style sheet language [CSS2]. CSS styling works best when there are no presentational HTML 3.2 elements.
The Template Engine does not attempt to solve in any other way the problem that is already solved by CSS. As far as the separation of style and structure is concerned, the role of the Template Engine is just to associate an appropriate CSS style sheet with the content.
Separating the actual content from the page chrome (navigation and other non-content such as logos) is another basic problem when creating and maintaining a Web site.
HTML itself lacks the elements for marking up navigation bars (and the like) as such. Therefore, the elements which are designed for marking up the main content have to be used for marking up the navigational parts as well.
Over the years there have been many attempts to solve the administrative problem of separating the main content from the navigational template.
src attribute for
certain elements (e.g. layer or div) to
include an HTML document in the place of the element somewhat like
the iframe element of [HTML4] does. This feature is not commonly
used, because it is nonstandard and the browsers that support it
implement it using different syntaxes. (A similar feature has been
proposed for XHTML 2.)The first four methods mentioned above are all about manipulating the HTML as a sequence of characters or bytes. Manipulating HTML on the level of characters or even bytes is very primitive considering that HTML is a formal language and it is possible to construct a higher-level representation for it. The higher-level representation could be an (abstract) syntax tree or an even higher-level object representation.
When HTML is generated by printing strings into an output stream there are typical problems including
All pages have the same title, because the
beginning of the page has been written into the output stream
shortly after the program started executing and before the actual
content is even fetched from the storage.
A mitigating factor—which has made popularity of string based templating possible—with HTML has been that the browsers try to parse this kind of documents as “tag soup” like any HTML page and, as a result, some of the errors might not even be visible in some browsers, even though the actual document content might be broken in other browsers. That is, it may appear nothing is wrong.
With XML the problems with escaping string literals and missing end tags become more apparent, because the errors easily break the markup so that it is not well-formed. A data object which is not well-formed is actually not an XML document by definition, and XML processors are required to report the first such error and cease normal processing [XML].
In summary, the overall problem with string manipulation is that at first it is assumed that the page can be generated linearly from the beginning to the end as the result of executing a relatively straightforward program, but later it turns out that more complex interdependencies are needed but they are hard to add. For example, it is very hard to handle exceptions properly if the beginning of the resulting markup is already generated as a string variable, or even worse: it is already printed to the stream and sent to the browser.
On the other hand, the authors don’t manage to adhere to the rules of the language being generated. Although the problems outlined above seem like small details, producing a proper result requires special discipline, knowhow and care in all stages of string manipulation.
The foremost problem with frames is that if the user makes a bookmark, the bookmark points to the frameset which is loaded in its initial state. That is, the bookmarking system in browsers doesn’t allow the user to return to the state the frameset was in at the moment of bookmarking. By extension, this means others can’t link to a particular frameset state. Since links are fundamental to the Web, this is a serious problem. [Frames]
Frames occupy parts of the view port all the time. A navigational frame can’t be just scrolled out of view in order to free up screen real estate for the content. Frames also cause problems with printing.
In most situations iframes can be used instead of frames. The
iframe element makes it possible to “insert an
HTML document in the middle of another” [HTML4]. In practice, a
new view port is created for the iframe. The document referenced from
the iframe element is not included into the document
tree of the parent page. Iframes are almost as powerful as frames but
they may not be resized and, being a part of another HTML document
and perhaps surrounded by text, the iframes tend to have a very
limited space to use for rendering the inserted HTML document.
In addition to the usability problems with frames the iframe scrolls with the outer document and the iframe itself can be scrolled. A scrolling area within a scrolling area is very annoying in a user interface.
When site navigation is merely included on each page without customizing it in a context sensitive way, the navigation makes less sense. When the user clicks a link in a navigation bar to move to a particular section of the site the navigation bar on the target page should somehow highlight the name of this section and remove the link from it. This doesn’t happen with the straightforward usage of server-side includes, frames and client side includes. (Non-JavaScript client-side includes aren’t used in practice because there is no standard for them.)
As the included part of a site is usually handled as a sequence of characters or bytes, it is thus very easy to introduce problems with the markup language and its well-formedness. At the minimum, markup validation should be enforced when the markup to be included is entered in the document repository. In addition, the context of the intended inclusion should be considered so that only a reduced set of markup tags should be approved in the input.
The problem XSLT is designed to solve is transforming a document instance of one XML-based language into a document instance of another XML-based language. Although XSLT is not tied to a particular target language, it has been designed primarily for producing XSL Formatting Objects. [XSLT]
XSLT tries to accomplish its goal with a syntax that looks declarative and is itself XML. Due to the nature of the problem, XSLT ended up as a programming language. The SGML syntax and, consequently, the XML syntax are designed for marking up text. That is, the expectation is that there is more text than markup. This makes XML a bad basis for programming language, because in program source code string literals tend to be a minority.
Also, the problem of combining different pieces of HTML is not the same as the problem XSLT is designed solve. As a result, XSLT is not an ideal solution to the problem at hand.
The problem at hand is that of combining different fragments of HTML into a Web page. These fragments include, in particular, the main content of the page and navigation. The objective we have with the Template Engine is to solve this problem on the server side without the usual pitfalls of string manipulation and without reinventing XSLT.
In particular, when avoiding reinventing XSLT, we aspire to address the common needs without developing the template language into full programming language. That is, we hope that the most common tasks that need to be carried out when assembling Web pages that consist of mainly textual content and navigation can be accomplished with little effort by using a rather small and simple template language. It is our design goal to make the template language easy enough to be written by people who have experience with HTML but don’t have programming experience.
In order to keep the template language simple, small and easy, we leave the harder and less common tasks to procedural Java code. We don’t even attempt to make the template language do all things, but we posit that some things are better done by writing Java code that manipulates the document tree directly. This code would be placed on the other side of the data source interface that the Template Engine uses for acquiring data.
Our Template Engine is specifically not designed for creating form-based user interfaces. The task of creating a form-based user interface differs significantly from the task of combining mainly textual documents with a site design. Form-based user interfaces require capabilities for round tripping, checking the entered data for correctness and a means for moving data between an HTML form and a database. These issues are outside the problem space our Template Engine is designed to address. Also, addressing these issues satisfactorily tends to require real programming language. Thus, it makes sense to use Java code directly instead of trying to extend the template language. Indeed, in this project, the administrative to user interface was implemented by manipulating the document tree representation of the user interface using Java. Building the user interface using the DOM representation and the Model-View-Controller pattern is discussed in [WebUI].
The first step that is needed in order to avoid the usual pitfalls of string manipulation is to raise the level of abstraction. An HTML document or an XML document parses into a tree. Instead of manipulating the document as a string, we could manipulate the document tree. We represent both the template and the content that is to be combined with the template as trees. The Template Engine examines the document tree of the template and takes fragments of the document trees of the content documents and merges these into the document tree of the template. Once the tree is ready to be transferred to the Web browser, it is serialized as markup and the serialization is sent over the network.
As with string manipulation-based templating systems, we want the template to be a skeleton HTML document which contains some special syntax particular to our Template Engine. We also want the template to contain information about what content needs to be fetched from the storage. Obviously, in order to be able to apply the same template to multiple pages, we need some external variable that modifies the fetching of the content. This variable is the URL of the document being built. That is, given a URL and a template, the Template Engine will then query a data source for appropriate content.
The key difference with the usual templating solutions is that in our Template Engine the syntax tree used for templating is the syntax tree of the target language with some additional nodes for templating. Usually the parts of the template that are written in the target language are considered string literals in the syntax tree of the template language.
Compared to other document tree-based templating solutions such as the HTML::Seamstress Perl module [Seamstress] or Enhydra XMLC [XMLC], our Template Engine does not require the template author to write procedural code in the common and easy cases that are addressed by the Template Engine. A however, if there is a need to go beyond the capabilities of the Template Engine, procedural code can be used to preprocess the document trees before passing them to the Template Engine.
If we had wanted to parse a template that contains HTML and our own template syntax into a tree, we’d have had to write a parser ourselves or modify an existing tag soup parser. Neither of those things was something we wanted to do. Using off-the-shelf XML tools is much easier. Also, [XMLNS] provides a suitable way for distinguishing between the template markup and the document skeleton. Therefore, it is desirable to use XML. XHTML is the reformulation of HTML in XML (as opposed to SGML) [XHTML1]. Using XHTML with our template vocabulary allows us to use namespaces to separate the two. If HTML input or output is desired, the conversion to and from XHTML is straightforward. The classic introduction to XML namespaces is [Namespaces].
There are two main types of XML APIs: event-based and tree-based. [SAX] is the de facto standard for event-based XML parsing. With SAX, the parser uses callbacks to report the syntactic constructs it encounters. The whole document does not need to be in memory at the same time, but random access to the document is not possible. Tree-based APIs build an in-memory syntax tree and allow random access to it. [SAX2] Since we’re combining pieces of multiple documents, the tree-based model is easier to work with.
A third “pull” model of XML parsing also exists. The data items involved are similar to the data items passed by SAX, but the application is driving the process by pulling data from the parser, whereas with SAX the parser is driving the process and pushes data to the application. The pull model was not used, because implementations were accused of incorrectness in [Wrong]. However, the pull model would probably have been easier to manage than SAX for the purpose of combining pieces of multiple documents if the tree model had been rejected.
The fourth model mentioned in [Wrong], XML data binding, is not applicable to narrative documents but is used with documents that resemble database rows or object serializations.
There are several Java frameworks for representing XML documents as trees: DOM, JDOM, dom4j, XOM and Electric XML. [DOM2][JDOM][dom4j][XOM][GLUE]
We were initially prejudiced in favor of the DOM due to prior acquaintance in the browser context. DOM Level 2 Core [DOM2] represents everything we need represented in the tree. However, it also represents things we would prefer to abstract away. DOM Level 2 Core is a W3C Recommendation and part of J2SE 1.4.
We were aware of three DOM implementations, all of which are Open Source: Crimson, Xerces [ApacheXML] and GNU [GNUJAXP]. Crimson and Xerces are available from the Apache Software Foundation. Crimson ships with Sun’s J2SE 1.4. Later, we found out there’s yet another DOM implementation available from the Apache Software Foundation: the DOM implementation of Batik (formerly known as DOMJuan).
We were also aware of the existence of alternatives for the DOM. The fact that the alternatives didn’t predate the DOM but were designed as replacements was somewhat unsettling, because it showed that some people had been unhappy enough with the DOM to bother to replace it.
By the time we started looking at the alternatives for the DOM, we had already examined the relevant DOM specifications and some of the available tools to the point that we were confident that what we were about to implement was implementable using the DOM. We realized beforehand that the DOM had problems, but we believed that we could route around the problems. Therefore, given the schedule constraints we were not really looking for the best tool for the job, but, rather, were looking whether some alternative offered a particularly attractive reason to move away from the DOM.
Electric XML was excluded from consideration, because of its non-Open Source license.
The main selling point of JDOM is that the API is designed specifically for Java and uses concrete classes and the Collections API introduced in Java 1.2. The DOM, on the other hand, is designed to be implementable for various programming languages and object systems, uses the factory pattern with interfaces and has its own list interfaces. However, our expectation was that we would not be using the list views of the DOM anyway. We were interested in walking the tree using neighbor references.
Our main objection to the DOM was that it doesn’t abstract away all the syntactic sugar of XML. For example, CDATA sections and regular text nodes are considered distinct from the point of view of the DOM API. However, JDOM doesn’t completely hide syntactic sugar, either. The case for choosing JDOM instead of the DOM didn’t look strong enough.
XOM improves on hiding syntactic sugar [Wrong]. Like JDOM, XOM uses classes instead of interfaces and represents the tree using lists of child nodes. XOM appeared to be a work in process and didn’t appear to have a large established mindshare. We didn’t dare to bet our project on a framework that we didn’t perceive as well-established and stable, although being the newest of the APIs, XOM could be expected to be able to address the problems that have been noticed with the other frameworks. Also, the license of XOM, the Lesser General Public License (LGPL), is more complex than the licenses of the other Open Source XML tree frameworks.
Dom4j is briefly described as a more complex fork of JDOM in [Wrong]. Because of this characterization, we dismissed dom4j without examining it closely.
We didn’t have time to benchmark and examine the different frameworks carefully, so we chose to go ahead using the DOM. The key factors behind the decision were:
The DOM representation of an XML document consists of a relatively large number of objects. Memory for these objects has to be allocated every time a DOM tree is built. This also leaves a lot of objects for the garbage collector to release. Our expectation was that under a heavy load object allocation and garbage collection would become a performance bottleneck for the system. We feared that the ability of outside HTTP clients to cause excessive repetitive object allocation would leave the system vulnerable to denial of service attacks. Therefore, the Template Engine was designed to work together with a cache system from the beginning. That way repetitive requests for the same page wouldn’t cause repetitive DOM creation.
We were also slightly worried about the efficiency of traversing the DOM tree, but we didn’t see the tree walking performance as problematic an issue as the repetitive object allocation and deallocation issue, because the tree walking phase operates on in-memory data structures and accessing in-memory data structures tends to be relatively fast compared to memory allocation and I/O.
The dynamic content is assembled at the Template Engine level on the basis of static template files. This approach sets high demands for the expressiveness of the template language. Yet, the template language has to be designed simple enough, so that the content providers with only basic programming skills can write the template files.
The template language is supposed to contain basic functionality for formatting and including static content items into the template body. Suggested applications for the Template Engine include a news service, an image bank, a calendar of events etc. All of these examples fit smoothly into our template model, but if more dynamic content (for example discussion forums) or more complex HTML structures, such as two-dimensional tables, are needed, the power of template language might prove itself insufficient.
If and when more dynamic Web pages are required, there are basically two different options to enhance the applicability of the Template Engine. First of all, the expressive power of the template language can be raised by including support for more complex structures. This might be an eligible solution to a certain point, but as the simplicity of the template language is one of our main concerns, we don’t want to turn the template language into a fully featured and complex programming language.
Second approach would be to generate part of the content with specialized procedural application code. Specialized application code could be written by qualified programmers, so the content provider would not need to write any program code at all. This option sounds attractive, though it has its evident pitfall. If the HTML content was generated by specialized application code, the content provider could not change the site easily. The procedural application code would have to be separately customized for each Web site hosted in the system. A solution that requires stand-by Java developers and doesn’t allow easy customization would not be a viable one considering the intended use of the system.
The Template Engine is designed as a reusable component. In the
expected usage scenario, the Template Engine is placed behind a thin
servlet and in front of a content management system that provides
data to the Template Engine. The Template Engine itself is
implemented as a class called TemplateEngine. The system
behind the Template Engine is required to implement an interface
called DataSource. The objects the data source returns
to the Template Engine implement interfaces from the Template Engine
package. The TemplateEngine provides one method for
initiating the process of building a page. The method is called
respond and it takes a URL and a Response
object as parameters.
A servlet that connects the respond method of the
TemplateEngine with HTTP GET is separated to a
subpackage.
DataSourceThis interface is the link between the TemplateEngine
and the system behind it. An object that implements this interface is
passed to the constructor of the TemplateEngine. When
the respond method of the TemplateEngine is
called, the TemplateEngine requests a Template
from the DataSource. The TemplateEngine
then traverses the DOM tree wrapped in the Template and
reacts to the elements of the template language therein. This causes
the TemplateEngine to acquire more data from the
DataSource by calling the select methods of
the interface.
The name of the select methods implies that the call
is conceptually similar to performing a SELECT query to
an SQL database. The implementation of the methods can, indeed,
involve such a query. The signature of the main version (there is
also another version for optimizing a common special case) of the
select method ispublic java.util.List
select(org.w3c.dom.Element query,
java.net.URL
context,
boolean
fullContent,
Dependencies
dependencies)
throws
IOException,
DataSourceException;
The return value is a List of Items.
The first parameter is a DOM Element object that
represents the query to be performed. Extracting a sensible query out
of the element is up to the implementation of the DataSource
interface. That is, the query syntax is opaque to the Template Engine
and the details about the XML element that represents the query can
be defined by the system behind the Template Engine.
The second parameter is the context-dependent outside ingredient to the query: the URL of the page being built.
The third parameter indicates whether the returned Items
should be able to return the full content of the items they
represent. The Template Engine can attempt to determine whether the
full content is needed. This is useful optimization in the case where
it is inefficient to acquire first only the metadata of the items and
later ask for the full data if needed. For example, with the database
system that was implemented, it would be inefficient to make
additional SQL queries if the full content is needed and it would be
inefficient to always fetch the full content just in case. On the
other hand, the optimization would waste time when it is easy to
implement lazy retrieval and parsing of the full content. For
example, if the Items held file references to the local
file system, it would make sense to load the full content lazily.
The DataSourceshouldAvoidFullContent which is called by the
TemplateEngine in order to find out whether requesting
full content should be avoided. In the system that was implemented
the method always returns true.
The fourth parameter is needed for supporting an explicitly
invalidated cache in front of the Template Engine. The Template
Engine acquires an object that implements the Dependencies
interface by using the DataSource as a factory. The
object is then passed back to the DataSource so that
cache invalidation keys can be collected.
TemplateThe Template interface merely binds together a DOM
tree and a modification date.
ResponseThe TemplateEngine writes its output to an object
that implements this interface. This interface is designed in such a
way that it is easy to implement as a thin wrapper around
javax.servlet.http.HttpServletResponse.
DependenciesThe TemplateEngine is designed for use with an
explicitly invalidated cache in front of it. The resources built by
the TemplateEngine need to be associated with
invalidation keys and, for some uses, an expiration date. The
Dependencies interface exposes is a set of invalidation
keys and an expiration date. The TemplateEngine itself
does not process this data. However, this data needs to pass through
the TemplateEngine. If the TemplateEngine
isn’t used with an explicitly invalidated cache, this interface
does not need to be implemented.
The actual invalidation events to the cache do not pass through
the TemplateEngine.
The results of queries consist of items which are wrapped in
objects that implement the Item interface. When more
information about the item is needed, the returned objects need to
implement other interfaces as well.
Item
DataSource must implement
this interface or an interface that inherits from this one. This
interface exposes the title, the modification date (if known) and
the URL (if the item is addressable by a URL) of the item.DocumentItemItem.ByteBufferItem
TemplateEngine has a passthrough mode
for serving untemplated sequences of bytes. This interface exposes
the content type of the item and the byte length of the item (if
known). The interface also contains a method void
writeToOutputStream(java.io.OutputStream out) which makes it
possible for the implementation to output the bytes efficiently so
that the TemplateEngine doesn’t need to loop over
the data. This interface inherits from Item.ImageItemIllustratedItemImageItem)
that is appropriate (small enough) for use in summary pages that
feature multiple items should implement this interface to allow
access to the illustration.DatedItemTemplateEngine for formatting. The
TemplateEngine does not know the meaning of these
dates.One of the difficult things to decide when designing an API for
Java is what to do with checked exceptions. Especially when designing
a package that will have an arbitrary amount of code underneath it
and some more code between it and the user interface, the API
designer cannot foresee all the possible exceptions that may arise
underneath the API being designed. On the other hand, what to do in
an error situation is a decision for the higher layers. Yet, giving
up and declaring that every method throws Exception is
considered bad style.
Both SAX2 and the Servlet API face the same problem with
exceptions that we faced when designing the DataSource
API: the lower layers can throw exceptions that are unknown at the
API design time. SAX2 and the Servlet API solve this problem by
introducing API-specific exceptions that can wrap other exceptions
(org.xml.sax.SAXException and
javax.servlet.ServletException). In the Java 1.4 support
for the exception wrapping a pattern was added to
java.lang.Throwable. We decided to use this pattern with
the DataSource API and introduced DataSourceException.
In the Servlet API, java.io.IOException can be thrown
without being wrapped in javax.servlet.ServletException.
Since the TemplateEngine is expected to be placed behind
a servlet, we decided to imitate this exception to the pattern as
well.
TemplateException
TemplateEngine finds
violations of the template language syntax.ResourceNotFoundException
TemplateEngine throws this exception when the
requested content is “not found”. In some cases,
templates can contain alternative content, so this exception is not
thrown in all cases where the DataSource does not
return content.DataSourceExceptionDataSource throws this exception if it encounters
difficulty. The DataSource implementation should wrap
the root cause exception inside this exception so that neat stack
traces can be printed.RedirectException
DataSource finds out that the TemplateEngine
is trying to build a resource for a URL that should only redirect to
another URL, the DataSource throws this exception to
cause a redirect.Example templates are shown in the Appendix.
doc, found and notFoundThe doc element establishes a document context. The
doc element has from one to three child elements: found,
optional notFound and an optional query element. The
namespace and the name of the query element are not defined by the
Template Engine.
If the query element is omitted, the query is implied to mean the item most closely related to the context URL. Otherwise, the query element is passed to the data source along with the context URL.
If the query returns an item, the content of the found
element is used and the item returned is used as the current item. If
the query does not return an item and it there is a notFound
element, the content of the notFound element is used. If
no item is returned and there is no notFound element, a
ResourceNotFoundException is thrown.
Document contexts can be nested.
foreach, found, item and notFoundThe foreach element is used for formatting lists of
items. The foreach element has two or three child
elements: found, optional notFound and a
query element. The namespace and the name of the query element are
not defined by the Template Engine. With foreach, the
query element is not optional.
The query element is passed along with the context URL to the data source, which returns a list of items.
If the returned list has the length of zero, the found
element is discarded and the content of the notFound
element is used. If there is no notFound element a
ResourceNotFoundException is thrown.
If the returned list has items, the notFound element
is discarded and the content of the found element is
used. An item element appears as a descendant of the
found element. The item element with its
content is repeated for each item on the list. That is, each copy of
the item element establishes a document context with
item on the list.
foreach may appear as a descendant of another
foreach, but such an arrangement makes no practical
sense due to the limitations of the queries.
image, found and notFoundThe image element is analogous to the doc
element, but the image element does not have a query
element. Instead, the query is considered to be one of that returns
an image that is related to the enclosing document context. The image
element is useful within a document context established using
foreach.
titleThe title element is replaced with the title of the
current item if the current item has a title. If the current item
does not have a title, the text content of the title
element is used instead.
The title element may appear anywhere where character
data is allowed.
aThe a element is converted into a hyperlink to the
URL of the current item. If the current item is not addressable by
URL, the content of the a element appears without a
hyperlink.
The a element can appear where XHTML anchors are
allowed.
dateThe date element is replaced with a formatted date
property of the current item. The element has two attributes: format
and source.
The source attribute designates the date to be
formatted. If the value is “modified”, the
modification date of the item is used. Alternatively, if the item
implements the DatedItem interface, the value can be an
integer which is used to identify a date.
If the item does not have the designated date, the content of the
date element appears instead of the formatted date.
The value of the format attribute is a string that
describes how the date is to be formatted. The format of the format
string is defined by java.text.SimpleDateFormat. The
language used for the names of week days and months depends on the
language of the date element. The language is determined
from of the xml:lang attribute of the date element or,
failing that, its closest ancestor with that attribute.
The date element may appear anywhere where character
data is allowed.
ifDateIf the current item has a date designated using the source
attribute of the ifDate element, the content of the
element is used. If the current item does not have the date, the
ifDate element and its content are removed.
urlThe url element is replaced with the URL of the
current item or, if the current item does not have a URL, with the
content of the url element.
The url element may appear anywhere where character
data is allowed.
switch and caseThe switch and case elements allow
decisions to be made it depending on the URL context. They are
primarily intended for context-sensitive modifications to navigation
bars.
The switch element contains case
elements as children. Each case element has an optional
attribute pat (short for pattern) which contains a
regular expression. The patterns are tried for match with the path
part of the context URL. The entire switch element and
its children are replaced with the content of the first case
element whose pattern matches with the path part of the context URL.
If the pat attribute is missing, the case
is considered to be applicable to any URL. Therefore, omitting the
pat attribute only makes sense on the last case
element.
bodyThe body element is replaced with the content of the
body of the current XHTML document. It is an error to use the body
element if the current item is not an XHTML document.
The body element has two optional attributes
(planned; not yet fully implemented): drop and shift.
The drop attribute may contain the values h1,
firstP or the two separated by a space to indicate that
the first paragraph, the first-level heading or both should be
omitted. This is useful for avoiding duplicate content when the
first-level heading or first paragraph are presented separately.
The shift attribute takes an integer value that
indicates how much the heading levels should be shifted down. For
example, 1 means first-level headings should become a
second-level headings and second-level heading should become
third-level headings. This is useful when content is included as part
of a document that already has higher-level headings.
The body element may appear anywhere where
block-level XHTML content is allowed.
h1The h1 element is replaced with the content of the
(first, but there is assumed to be only one) first-level heading of
the current XHTML document. It is an error to use the h1
element if the current item is not an XHTML document.
The h1 element may appear anywhere where inline-level
XHTML content is allowed.
firstPThe firstP element is replaced with the content of
the first paragraph of the current XHTML document. It is an error to
use the firstP element if the current item is not an
XHTML document.
The firstP element may appear anywhere where
inline-level XHTML content is allowed.
The Template Engine supports the use of cache servers which are capable of caching dynamic content. The cache implementation requires that all the HTTP content which is served out from the Template Engine be tagged with appropriate dependency keys and with a possible content expiration date.
The dependency keys are represented as ASCII strings and they describe the dependencies between the database content and the generated response. The semantics of dependency keys need not be known by the Template Engine as the keys are automatically generated at the database interface behind the Template Engine and interpreted only at the cache server in front of the Template Engine.
The Template Engine must instantiate a new dependency collector object for all incoming HTTP requests and pass it along with the queries to data source. After the queries are processed the dependency collector object contains a set of dependency keys and a possible expiration date. This information must then be written to the HTTP response by using the following custom HTTP headers:
X-Cache-Dependencies
X-Cache-Expires
In addition to these fields, the cache server needs to know a default
lifetime of each resource for usual HTTP caching in proxies and user
agents. Therefore, the Template Engine must send the Expires
header. The difference between the Date header value and
the Expires header value is used as the resource
lifetime when the cache serves the content out.
The cache invalidation is implemented independently from Template Engine and is not described in this paper. The cache implementation is presented in [Cache].
In order to find all the elements that belong to the template
language, we need to traverse the document tree of the template.
Document Object Model Traversal, which is part of [DOM2Range],
specifies two interfaces for traversing the DOM tree: NodeIterator
and TreeWalker. NodeIterator provides a
sequential view of the nodes in the document order. TreeWalker
also allows the moving the along sibling, child and parent links.
The Template Engine modifies the tree while traversing it. In order to be in full control of the behavior of the walking algorithm when the tree changes underneath it, we chose to implement the tree walking algorithm in the Template Engine code without using the facilities provided by Document Object Model Traversal. Also, the tree traversal code was expected to be one of the hot spots of the Template Engine, so the possibility of eliminating some of the indirection related to using Document Object Model Traversal seemed attractive.
Although the DOM could be traversed recursively using the
firstChild and nextSibling references and a
textbook binary tree traversal algorithm, we chose to use an
iterative algorithm instead in order to avoid unwarranted method
invocations.
The algorithm we use is slightly simplified from the one presented
by John Cowan in [Walking]. Cowan argues that the algorithm should be
considered the standard algorithm for traversing the DOM and,
therefore, DOM implementations should make the getters for neighbor
references fast. The algorithm traverses the tree in the document
order. That is, the current node is visited first, then the algorithm
moves to the firstChild if it is not null
or to the nextSibling if the firstChild is
null. If there is no nextSibling the
algorithm climbs towards the root until it finds a node that has a
nextSibling (or the algorithm reaches the root node of
the traversal).
The version of the algorithm presented by Cowan revisits the nodes
as it climbs towards the root. This is useful for printing the end
tags when serializing a tree, and the algorithm is used that way in
gnu.xml.util.DomParser which we use when serializing the
DOM tree. We don’t need to revisit the nodes when doing the
template processing so we simplify away the revisiting. In the
process of walking the tree we check whether we are looking at an
element node. Since we’re doing this anyway, we can optimize
the walking algorithm slightly and avoid the firstChild
check when we’re not looking at an element node.
To make the walking work flexibly when the tree is modified, the method for dispatching the elements for processing returns a node that the walking algorithm uses as the current node. That is, when the dispatching method does nothing it simply returns its argument.
The implementation of the algorithm is shown below.
protected final void walkTree(Node node) throws
TemplateException,
DataSourceException,
IOException
{
Node current =
node;
Node next;
for (;;) {
if
(current.getNodeType() == Node.ELEMENT_NODE) {
current
= this.dispatch((Element)current);
if
((next = current.getFirstChild()) != null) {
current
= next;
continue;
}
}
for
(;;) {
if ((next =
current.getNextSibling()) != null) {
current
= next;
break;
}
current
= current.getParentNode();
if
(current == node) return;
}
}
}
The dispatch method that is called by the tree
walking algorithm inspects the namespace and the local name of the
element and calls a method for handling a particular template element
or, if the element is not a template element that needs handling,
merely returns the element to the tree walking method.
The methods for handling simple place holder template elements
such as title merely get the required data from the current item and
insert it into the template. The operations are carried out without
using the problematic NodeList views provided by the
DOM. Most of the time this is just routine use of the DOM API. In
some cases, the template elements themselves are left in the document
tree, because dropping them can be done more efficiently in the
serialization phase.
For example, the implementation of the url element
(shown below) returns the element (for dropping at the serialization
phase) if there is no URL to insert and, if there is a URL to insert,
creates a text node with the URL as the content and replaces the
template element with the newly created text node.
protected Node handleUrl(Element elt) throws
TemplateException,
DataSourceException,
IOException
{
Node text;
URL
url = this.getCurrentItem().getURL();
if (url == null)
{
return elt;
} else
{
text =
this.template.createTextNode(url.toString());
elt.getParentNode().replaceChild(text,
elt);
return text;
}
}
Establishing a document context is more complicated. When an
element that establishes a document context is encountered, its
children are searched for the query element, the found
element, and the notFound element. The query is passed
to the data source. If the result isn’t empty, the result item
is pushed onto the context stack and the walkTree method
is called recursively for the found element or, in the
case of foreach, for the item element which
is copied for each item in the result list. After walkTree
returns, the item is popped from the context stack. The query element
and the notFound element are removed with their
subtrees. (If the result is empty, the found element and
the query are removed and the walking is continued from the notFound
element.)
The Template Engine has two serialization code paths: XML and
HTML. The XML code path was implemented first, because of the
availability of off-the-shelf tools from [GNUJAXP]. In both cases,
gnu.xml.util.DomParser is used for emitting SAX events
from the DOM tree. Attention is paid only to the events reported to
the SAX ContentHandler. Other events are considered
exposure of syntactic sugar and are ignored.
In the XML mode, the SAX events are first passed to a filter
called TemplateOutputCleaner, which drops all elements
that are in the template namespace. Dropping the remains of the
template elements using a SAX filter is more efficient than removing
them by manipulating the DOM tree. Then the SAX events are passed to
gnu.xml.pipeline.NSFilter, which makes sure the SAX
events represent a document that conforms to [XMLNS]. Finally, the
SAX events are passed to gnu.xml.pipeline.TextConsumer,
which produces an XML document using the UTF-8 encoding.
Initially, when only the XML code path had been implemented with off-the-shelf tools, the resulting document was served to the browser as application/xhtml+xml. This worked fine with the Mozilla-based browsers we used (and with Opera and Safari). However, supporting browsers that don’t support properly served XHTML—most notably Internet Explorer and Lynx—was considered a requirement for system. To support these browsers, it is necessary to serve text/html.
The output from the XML code path is not appropriate for serving as text/html, because the output doesn’t conform with the Appendix C of [XHTML1]. In [Harmful], it is suggested that HTML 4.01—not XHTML—be used when serving text/html. In order to do the right thing with text/html, we chose to implement an HTML serializer that produces an HTML 4.01 Strict document from SAX events that represent an XHTML 1.0 Strict document.
In the HTML mode, the SAX events are passed directly to the HTML
serializer, because the HTML serializer itself ignores elements that
aren’t in the XHTML namespace (that is, the template elements)
and uses the local name of the elements that are in the XHTML name
space. Hence, TemplateOutputCleaner and
gnu.xml.pipeline.NSFilter are not needed.
The HTML serializer (like the XML serializer) uses the UTF-8 output encoding, so only markup-significant characters need to be escaped, which the serializer does automatically. The serializer prints a start tag when start element is called and prints an end tag when and element is called unless the element is defined as empty in the HTML 4.01 Strict DTD, in which case and end tag is not printed.
When a Web page served as text/html comes without a doctype declaration, modern browsers use a layout mode known as the Quirks mode, in which the CSS specifications are violated for the sake of backwards compatibility with broken legacy browsers [Doctype]. Since pages produced by the Template Engine are intended to be styled using CSS, it is desirable to activate the Standards mode, in which the browsers try their best to comply with the CSS specifications. To activate the Standards mode, the HTML serializer starts every document with an HTML 4.01 Strict doctype declaration that is considered non-quirky by the browsers. Including the doctype declaration is also a prerequisite for claiming validity.
The DOM API is not thoroughly elegant. In fact, it has actual or perceived problems to the point of motivating the creation of multiple replacements. The problems fall into three slightly overlapping categories: problems with the level of abstraction, general API design issues and not taking fully advantage of the features of the host language.
Problems with the XML APIs for Java are outlined in [Wrong].
An XML document parses into a document tree. Some details of the markup constitute syntactic sugar, and differences in syntactic sugar should make no semantic difference on the abstract level. The DOM exposes syntactic details which might be of some interest if one wanted to recreate the XML source with the original syntactic details. However, the exposure of such details is risky, because processing might then be influenced by details that should make no difference. Despite the exposure of some syntactic details, it turns out that the DOM isn’t concrete enough to recreate the exact original XML source after all: for example, the DOM doesn’t preserve white space between attributes. Thus, the DOM tree is neither a fully concrete syntax tree nor a fully abstract one but something in between.
When considering which syntactic variations are significant, we use [AXML] and [XMLC14N] as our guides. In particular, if two syntactic constructs yield the same canonical form, we consider the distinction between the constructs insignificant and of no interest to the application.
[XML] provides two ways of escaping markup-significant characters:
predefined entities and CDATA sections. These are just two
alternative syntactic constructs and should have no semantic
difference. However, they can be represented differently in the DOM.
Let us consider the following XML document: <foo>x
<![CDATA[< y &]]>& x < z</foo>The
root element of the document is named “foo”. The element
has text content which parses to: “x < y && x <
z”. If the document builder is not run in the coalescing mode,
the root element will have three child nodes: a text node whose value
is “x ”, a CDATA node whose value is “< y &”
and a text node whose value is “& x < z”. An
unsuspecting programmer might only check for text nodes in which case
his application would work incorrectly when encountering a document
with CDATA sections.
The Template Engine checks for both, and the output is escaped using predefined entities—not CDATA sections. Still, it makes sense to run the document builder in the coalescing mode (in which case only a single text node with the value “x < y && x < z” is created), because doing so reduces the number of nodes which in turn makes walking the tree faster.
XML documents may declare grammar rules that the document itself is supposed to follow using constructs that form the document type declaration. The grammar rules form the document type definition or DTD. The DTD consists of an internal subset and an external subset. The internal subset is in the document entity (casually called the “XML file”) itself and the external subset is included by reference. The DOM exposes what is needed in order to re-create an equivalent to document type declaration (with possibly differences in white space): the name of the root element, the public identifier of the external subset, the system identifier of the external subset and the literal of the internal subset.
Although exposing the unparsed literal text of the internal subset could be considered a strange requirement and a possible problem for the DOM implementors, it is unlikely to encourage application programmers to do strange things. The exposure of the public identifier of the external subset, however, might. It is a common belief that one can deduce the type of an XML document from the public identifier of the external subset—after all, the syntactic construct is called the document type declaration. (This belief is amplified by the behavior of the common browsers with respect to HTML—choosing the layout mode [Doctype]—and by the prose of the HTML 4.01 specification.) However, the use of a public identifier should make no semantic difference. The external subset can just as well be referenced using a system identifier. Also, pasting the declarations of the external subset to the end of the internal subset should not alter the meaning of the declarations in any way. Thus, whether the public identifier appears is a matter of choosing between different equivalent syntactic constructs. As usual, binding behavior to the choice of syntactic sugar is bad practice. Instead of doing type-based dispatching by looking at the document type declaration, the dispatching should be done based on namespace.
The Template Engine does not examine the doctype node even if one exists.
XML documents may have comments. An XML processor, however, does not need to pass comments to the application. Therefore, comments are inappropriate for communicating data that the recipient application is expected to see and act upon. Yet, comments may show up as comment nodes in the DOM. Unless the application programmer has control over the DOM building and can cause comments to be ignored before they reach the DOM, the application code needs to take into account the possible presence of comment nodes.
The Template Engine walks past the comment nodes if they exist. However, ignoring comments when building the DOM trees is desirable, because reducing the number of nodes makes walking the tree faster.
XML allows the parse-time inclusion of named strings using entity
references. For example, the string “© 1999–2004
Example, Inc.” could be declared in the DTD as an entity called
“copyright”. Then the XML processor would substitute
every occurrence of “©right;” in
element content or in attribute values with “© 1999–2004
Example, Inc.”—assuming, of course, that the XML
processor has seen the DTD. [XML] does not require non-validating XML
processors to process the DTD. Hence, it is possible that the XML
processor has not seen the entity declaration. In that case, the XML
processor has to report the unexpanded entity to the application. It
is then up to the application to decide what to do.
The DOM has a node type for representing unexpanded entities. These nodes could be used to communicate that the XML processor could not expand an entity reference because the DTD wasn’t processed, or an editor that wants to round-trip XML might even request that entity references not be expanded. The problematic part is that an application that doesn’t control the generation of the DOM tree might be passed a tree that contains unexpanded entity references. The application writer needs to take this into account.
The policy with the Template Engine is that the DOM trees must not contain unexpanded entity references. This is part of the API contract between the Template Engine and the data source. If the data source violates the API contract an exception will be thrown (at the serialization stage at the latest).
The DOM exposes the origin of attributes to the application. That is, the application can query whether an attribute was specified in the XML document entity or defaulted from the DTD. Again, this could be regarded as a syntactic detail that should make no semantic difference and, therefore, should not be visible to the application.
The Template Engine does not attempt to find out the origin of attributes.
[XMLNS] specifies a layer on top of XML 1.0 that allows element and attribute names to be associated with a namespace. The name of a namespace is a URI. For syntactic convenience the namespace URI is bound to a prefix or declared as the default namespace. The namespace prefix can be chosen arbitrarily on a per document basis and should have no meaning to the application. That is, the globally unique name for an element is the ordered pair of the namespace URI and the local name. Therefore, an application which pays attention to the choice of namespace prefix can be considered broken. The insignificance of the choice of prefix is expressed more clearly in [Namespaces] that in [XMLNS] itself.
The DOM exposes the qualified names of elements and attributes—the concatenation of the namespace prefix, colon and the local name. This makes it easy for an application programmer to pay attention to the namespace prefix instead of the namespace URI. Issues related to using qualified names are discussed in [QNames].
The Template Engine examines the namespace URI and the local name—not the qualified name.
Live lists are probably the most controversial part of the DOM. If
the application calls the getElementsByTagName then
iterates partway over the returned NodeList and removes
a node that is on the list, the list view itself changes and all the
indexes from that point onward are shifted down.
Attempts to make the list views fast can make other parts of the DOM implementations slow. In any case, the list views severely complicate the code of the DOM implementations compared to the intuitive tree implementation based on the neighbor references.
The Template Engine does not use the NodeList
interface at all. The NamedNodeMap interface is only
used when copying attributes when shifting header levels. Thus, it
doesn’t matter for the Template Engine if the list views are
O(n2). What matters is that the neighbor references
are fast.
The DOM allows many operations to be performed directly through the node interface without having to use the methods provided by the subinterfaces. Using only the node interface is called the flat view. The rationale for providing access to features that are specific to particular node types through the common super interface is that in some object environments, such as COM, performing runtime casts is expensive.[DOM2]
For the purposes of the Template Engine the common super class
with the methods for getting the neighbor references is a very
convenient thing to have, even though getFirstChild
always returns null for some node types. Still, having
methods like getAttributes which returns null
for all node types except element nodes is somewhat strange from the
point of view of object oriented API design.
DOM Level 1 didn’t have namespace support. Namespace support was added in DOM Level 2, but the namespace-unaware Level 1 calls were retained for backwards compatibility. The two versions of some of API calls can be confusing for new users of the API. Also, the qualified name (as opposed to the local name) is considered the first class node name for elements and attributes.
The DOM is often accused of Java-unlikeness, because of its own
list views, use of interfaces instead of concrete classes and short
constants. Also, as pointed out in [Wrong], the DOM doesn’t
make guarantees about hashCode, equals and
toString.
The getNodeType method of the Node
interface returns a short constant that describes the
type of the node. Checking this constant is indeed not Java-like
compared to using instanceof. However, this constant is
useful and efficient in switch–case.
Still, when using the node type constants one has to be careful to
remember that the CDATA sections and usual text nodes have different
node types, but, for practical purposes, they should be treated
equivalently.
We didn’t find the Java-unlikeness a significant problem when developing the Template Engine.
Although the list of problems discussed above looks long, actual adverse effects were avoided in this project, because we were aware of the existence of problems and knowingly attempted to find out what the problems were in order to avoid or address them. Avoiding or addressing the problems wasn’t particularly hard and didn’t particularly interfere with the work toward the main goals of the project.
During the project, needs for various utility methods arose. Writing a set of utility methods was easy and straightforward but took some effort. For example, a method that returns the white space normalized concatenation of all the descendant text (and CDATA) nodes of an element is often needed but is not provided by DOM Level 2 Core. It would be useful to have this kind of oft-used functionality in the core API itself. The lack of practical utility methods summarized in [Drudgery].
All in all, the DOM worked very well as the basis of the Template Engine. Considering articles like [Drudgery], the Template Engine was almost surprisingly straightforward to implement using the DOM. Perhaps part of this is due to the DOM influencing the way the Template Engine was envisioned and designed. Also, the Template Engine acts on a small set of template elements and otherwise walks past nodes and copies subtrees without further examining them. The design of the template elements themselves was influenced by the DOM representation. Furthermore, the Template Engine traverses the template in the document order, while applications that use XML documents as storage for data that doesn’t resemble narrative documents are more likely to access the document in a less sequential fashion.
The Template Engine was probably even easier to program using low-level DOM access rather than a higher-level least we used provided by some of the DOM alternatives. However, list views and query features may be more convenient for applications that do not traverse the tree in the document order.
When generating markup there is a number of correctness issues to consider. These are of very well addressed by the tools we use.
The treeness of the DOM guarantees the proper nesting of tags.
That is, the document order tree traversal guarantees that the parent
element can’t be closed before the child elements have been
closed. The representation of strings in both DOM and SAX makes it
easy to properly escape markup-significant characters where needed
during the serialization. The gnu.xml.util.XMLWriter
class (from which gnu.xml.pipeline.TextConsumer
inherits) takes care of this. It also takes care of the attribute
values being properly quoted.
The DOM does not, however, enforce the namespace constraints
specified in [XMLNS]. When serializing to XML,
gnu.xml.pipeline.NSFilter fixes the namespace
declarations for us.
But XML well-formedness isn’t only about quoted attributes, proper escaping of markup-significant characters and the proper nesting of tags. Character encoding errors are also violations of well-formedness rules. Additionally, there are some ASCII control characters that are forbidden in XML.
When the character data is correct, encoding it properly is not a problem, because the Template Engine always uses UTF-8 as the output encoding and UTF-8 can encode any Unicode character. Hence, we don’t need to deal with the situation where the output encoding couldn’t encode a particular character.
Internally, Java strings are encoded using the UTF-16 encoding,
which can also encode any Unicode character. Converting from UTF-16
to UTF-8 is only a matter of shifting bits. There is one problem,
though. A Java char is an unsigned 16-bit value, but a
Unicode character encoded in UTF-16 is not always 16 bits long.
Characters from the Basic Multilingual Plane of Unicode (code points
U+0000–U+FFFF) are encoded with the scalar value of the code
point represented as an unsigned 16-bit integer. Characters from the
astral planes (code points above U+FFFF) are encoded as a surrogate
pair. A surrogate pair consists of a high surrogate which is a 16-bit
integer in the range 0xD800–0xDBFF followed by a low surrogate
which is another 16-bit integer in the range 0xDC00–0xDFFF. [Unicode]
(The scalar values 0xD800–0xDFFF have been set aside for this
purpose only so there are no characters in the range U+D800–U+DFFF.)
The problem is that Java allows unpaired surrogates in strings but
XML doesn’t.
Neither the ASCII control characters nor unpaired surrogates are a
problem when the DOM trees passed to the Template Engine have been
built by parsing XML documents using a conforming XML processor. If
the XML documents contained forbidden characters, the XML processor
would catch the error before the data reached the Template Engine.
Thus, the problem is restricted to synthetic DOM trees and cases
where the getTitle method of the Item
interface returns a bad string to the Template Engine.
The GNU implementation of the DOM does not check strings for
forbidden control characters. The DOM implementation of Xerces checks
element names for forbidden control characters but does not check the
content of newly created text nodes. The DOM implementation of
Crimson checks both. Regardless of the DOM implementation in use, the
GNU XMLWriter class catches the forbidden control
characters, so if forbidden control characters find their way into
the Template Engine an exception will be thrown on the server side.
None of the tested DOM implementations nor the GNU XMLWriter
checks for unpaired surrogates. However, by default, the UTF-8
character encoding converter of J2SE 1.4.2 replaces unpaired
surrogates with a question mark, which is not a forbidden character
in XML. Therefore, unpaired surrogates don’t raise exceptions,
but they don’t render the produced document ill-formed, either.
Thus, the character encoding conversion does not cause problems after
all.
Since the Template Engine never produces a doctype declaration in
the XML mode, the XML documents produced by the Template Engine are,
by definition, not valid in the sense defined in [XML]. However, Web
browsers use non-validating XML processors, so formal validity
doesn’t really matter for practical purposes as long as the
structure of the document adheres to the requirements placed on the
occurrences of attributes and on which elements may appear as
children of which elements. In practice, a document is sufficiently
close to valid if it could be made valid according to a well-known
DTD by inserting a doctype declaration and adjusting the xmlns
attributes to meet the constraints of the DTD without actually
changing the namespace of any element or attribute. (For example, the
XHTML 1.0 DTDs allow the xmlns attribute only on the
root element, but [XMLNS] would allow redeclaring the namespace
later.)
The Template Engine does not guarantee that all documents produced in the XML mode are sufficiently close to valid XHTML 1.0 Strict. This could be considered a failure to meet the goals of the Template Engine. However, enforcing correctness on the XHTML level wasn’t even expected in the design phase. Instead of actually enforcing XHTML-level correctness, of the template language makes it easy to stay on the correct side, because for each template element it is known in advance whether its replacement will be character data, inline content or block content. (Of course, if the data source violates the API contract, the predictability of inline and block replacements doesn’t hold.)
One validity issue which deserves to be mentioned separately is
that in XHTML and HTML, the id attribute must be unique
within an document. The Template Engine does not enforce this
constraint. Unlike the other validity considerations, the requirement
of id uniqueness can’t be satisfied by writing the
templates carefully. Therefore, our failure to address this issue
could be considered more serious than the issue the template writer
can take care of.
Unicode allows multiple representations of the “same” character. For example ‘ä’ can be represented as one character (LATIN SMALL LETTER A WITH DIAERESIS) or as two characters (LATIN SMALL LETTER A followed by COMBINING DIAERESIS). The former is known as the precomposed form and the latter as the decomposed form. There are also presentation forms that are considered compatibility equivalents of other characters. For example, LATIN SMALL LIGATURE FI is a presentation form of LATIN SMALL LETTER F and LATIN SMALL LETTER I.
[UAX15] defines four normalization forms of Unicode that differ in their representation of characters that can be decomposed or that have compatibility equivalents. [Charmod-Norm] (which is still a working draft) specifies that the Normalization Form C ought to be used on the Web.
The Template Engine does not enforce this requirement. Still, the documents and built by the Template Engine are likely to be in the Normalization Form C, because Unicode data produced by current editors and Unicode data converted from legacy encodings tends to be in Normalization Form C even when this requirement is in specifically enforced.
One way of guaranteeing that the data emitted by the system is always properly normalized would be making it part of the API contract with the data source that only normalized data could be passed to the Template Engine and then normalizing all data that enters the storage system. This would be efficient in terms of processing, because the normalization would be performed only once. However, the normalization code would probably have to be invoked in many places.
Another solution, which would keep the normalization code in one place, would be performing the normalization in SAX filter when the DOM tree is serialized in the Template Engine.
Practical HTML correctness is more difficult to characterize the than practical XHTML correctness, because HTML does not have all low-level concept of correctness comparable to XML well-formedness and the formal concept of HTML validity is not tightly coupled with practical parseability, because Web browsers don’t use real SGML parsers. (HTML formally allows shorthand notations which are not actually supported by common browsers.)
When in the XML mode the Template Engine would produce a document that is as good as a valid XHTML 1.0 Strict document when observed using a non validating XML processor, the Template Engine produces a valid HTML 4.01 Strict document in the HTML mode. This means that the output is valid when the data source does not violate to the API contract and the template is written in such a way the that the parent–child relationships of the XHTML elements adhere to the XHTML rules, the XHTML elements don’t have prohibited attributes and the template elements are only used in places where the replacement content of the template elements is allowed.
In summary, HTML validity is not enforced by the Template Engine, but is, nonetheless, easy to achieve if the template writer is aware of the rules. The Template Engine protects against low-level errors (such as missing end tags and unescaped markup-significant characters) that would be easy to make with other tools.
We assumed the memory usage of the DOM might lead to performance problems. However, casual and inconclusive testing suggested that the performance is satisfactory.
Our testing involved fetching a simple page combined from one template and one content document. The resulting page consisted of one heading and 15 paragraphs of nonsense and was about 9.4 KB in size. For comparison, we also served the resulting document from the local file system is using Apache. The system used behind the Template Engine was not a minimized test back end but the entire system being developed in the project. The database was running on the same machine. The cache that will be used in deployment between the Template Engine and the Web was not used in the test.
The tests were run on a GNU/Linux PC with a 500 MHz AMD-K7 processor and 384 MB of RAM.
Testing was done in 30-minute runs of sequential document fetching through the loopback interface. The Java Virtual Machine (the server version of Sun’s HotSpot) was warmed up until the mean response time no longer got better between two 30-minute runs.
The results are shown in Table 1.
| Mean | Median | |
|---|---|---|
| Flat file (Apache) | 0.004 s | 0.001 s |
| Crimson (Jetty) | 0.05 s | 0.04 s |
| GNU (Jetty) | 0.07 s | 0.06 s |
| Xerces (Jetty) | 0.09 s | 0.05 s |
Unexpectedly, Crimson performed better than Xerces. The results given in [Benchmark] suggest that our result could be attributed to the deferred node expansion feature of Xerces. Both Crimson and Xerces were used through the JAXP API without implementation-specific parameters. Based on [Benchmark], we assume that the overall performance could be improved by configuring Xerces carefully.
In [Usability], response time guidelines by Robert B. Miller (1968) are quoted. In order for the response to seem immediate, the response time has to be 0.1 seconds or less. When the pages get more complex and the network latency is taken into account, our system on the (rather old) test hardware may not be able to deliver the page in 0.1 seconds.
However, the response time of the back end system is visible to the site user only when a resource is not yet in the cache. Also, the performance could be improved by using newer and more expensive hardware.
As designed and expected, our Template Engine successfully protects the template writer from low-level errors that are common to usual text based templating methods.
The enforcement of correctness inherently limits flexibility. However, the flexibility to do the wrong thing is not necessarily desirable. On the contrary, taking care of low-level syntactic issues like ensuring XML well-formedness is a task better suited for software than for people, and leaving the task to people on the grounds of flexibility and freedom is highly likely to result in oversights and errors that users would prefer not to make.
Still, in addition to taking away the freedom and flexibility to make low-level syntax errors, which no one should want to make, our Template Engine is also less flexible than many text-based alternatives in terms what kinds of correct documents can be produced. This is both due to the constraints XML places on the ways XHTML and the template language can be mixed and to the limits the duration of the project placed on what features could be implemented.
What our Template Engine loses in terms of flexibility, it gains in terms of simplicity of the template language and ease of the database integration (from the point of view of the template writer). The template language is rather small, which makes it easy to learn and to grasp in entirety. However, the set of possible database queries is not defined by the Template Engine but is left open for the data source to define. This makes it possible to provide relevant high-level query descriptors.
Simple text-based templating solutions, such as a server side includes [SSI], tend to give access to local files relative to the template being processed. Elaborate preprocessors that have grown into programming language interpreters, such as PHP and Lasso, tend to allow SQL-level access to databases [PHP][LDML]. Providing full SQL-level access means the person writing the template or, rather, the program has to know how to write SQL queries and format the results. (Lasso also provides syntax for querying the database without precise SQL queries [LassoVsPHP].)
In our Template Engine, whether access to local files or database
is given to templates is up to the data source. The ability of the
data source to provide relevant and high-level query descriptors can
be used to hide the details of file paths or SQL queries. The foreach
construct allows easy implicit looping over the result set. As a
result, the template writer can work with the high-level query is
instead of accessing the database using SQL.
Of the text-based templating packages IBM’s Net.Data provides implicit looping over SQL result sets. A relatively tight coupling between the result set row and the HTML formatting is expected. Net.Data delegates more complex programming needs to Perl or REXX. [NetData] Also Lasso’s LDML provides easy looping over SQL result sets [LDML].
In summary, compared to usual text based templating methods our Template Engine guarantees the absence of low-level syntactic errors (well-formedness errors in the XML mode and similar errors in the HTML mode) and provides easy access to the database. This is done at the expense of flexibility.
XSLT and our template language are superficially similar in the sense that both mix elements from the language itself and from a target language using XML namespaces. However, in a closer examination the languages are very different. XSLT is a powerful programming language for transforming XML documents into different kinds of XML documents. Our template language is a simple and rather limited language for piecing together XHTML documents.
Even though XSLT is used in the problem space that our Template Engine is designed for, our template language and XSLT have been designed to address different needs. Our template language is not (and is not intended to be) a substitute for XSLT for the purpose XSLT is designed for—that is, transforming documents from one XML based language to another. However, for the specific purpose of combining XHTML documents our template language can be used instead of XSLT. For that purpose, our template language is simpler and more focused. Querying a database for multiple documents is central to our template language. XSLT is designed primarily for transforming one document into another, but other documents can be accessed from within a transformation template. XSLT accesses documents by URL [XSLT], so if access to database is needed, a URL scheme for accessing the database has to be implemented.
In summary, combining pieces from various XHTML documents can be accomplished with XSLT, but that is not what XSLT was designed and optimized for. Our template language does not come even close to XSLT in expressiveness but is simpler and more focused on combining pieces of XHTML documents into Web pages. We believe the simplicity of our template language compared to XSLT makes our language easier to learn and use for template writer with HTML background but no programming background. The simplicity and limited expressiveness of our language compared to XSLT is considered a feature that makes the language easier to use.
XSLT and our template language take the approach of mixing elements of the template language and the target language using XML namespaces. There are also document tree-based templating packages that do not mix a template language with the target language. With XMLC and HTML::Seamstress the template is pure (X)HTML document and program code is connected with the template using id or class attributes [XMLC][Seamstress].
In [XMLCvsJSP], JSP’s approach of embedding Java code in HTML is described as “inherently flawed when applied to large projects”, because the program logic and markup in get hopelessly entangled which runs against the principle of modular design. Even though our Template Engine protects against the low-level syntax errors which are common to pages produced with active page technologies like JSP which mix and procedural program code with pieces of HTML, our template language still involves entangling pieces of XHTML and template elements.
One of the major problems with intertwining (X)HTML and template directives is that the templates can’t be easily edited with HTML editors. Even when the template directives are preserved by the editor, the template may look nonsensical in the editor when the template directives are treated as unknown pieces of data. Also our template language inherently has this problem. On the other hand, the templates XMLC uses can be edited with the same tools Web designers usually use and the templates can even contain mock content that is discarded by XMLC [XMLCvsJSP].
With XMLC the Java code is written for a particular template, which means that some non-trivial changes to the template may require tweaking the Java code. This is fine for projects where programmers and markup writers are always available to implement changes. However, in our project of the goal was to develop a system that would allow the sites to be customized by markup writers without a Java programmer standing by all the time.
When touching the Java code is actually needed, XMLC is more
flexible than our Template Engine. Basically, XMLC is a tool that
generates code that facilitates bootstrapping the DOM, getting hold
of the elements that the Java code needs to touch and then
serializing the result. The Java code can then modify the DOM tree
freely. With our Template Engine, custom Java code would be placed on
the other side of the DataSource interface. This means
that the custom code would have to pass preprocessed XHTML documents
to the Template Engine. This is awkward if the output of the custom
code can’t be naturally packaged as full XHTML documents. The
other alternative is modifying the Template Engine itself.
Our Template Engine isn’t designed for building form-based user interfaces. For pages that require complex management of numerous details, such as the values of form fields, our Template Engine clearly is the wrong tool and it makes sense to use a solution that involves procedural code that manipulates the document tree directly. In our project the administrative user interface was implemented by accessing the DOM tree directly from Java code—although without the help of XMLC [WebUI].
The template elements representing simple pieces of data such as
the title element and the url element
turned out to be as tidy as envisioned. However, the syntax for
establishing the document context turned out to be uglier than
envisioned.
The elements for establishing the document context require two
branches: one is used when the content is found and the other when
the content is not found. This requires two container elements which
in turn are wrapped in a third element to signal that they belong
together. That is, to indicate two branches which in turn are marked
up to belong together, the pattern looks like
this:<foo>
<bar>
...
</bar>
<baz>
...
</baz>
</foo>
The syntax is awfully verbose compared to C-style braces (or
Python-style indents):foo {
...
} bar
{
...
}
The verbosity wouldn’t have been a significant problem if the template language was just a program-to-program interchange format rather than a human-written format. In practice, the template language is a human-written format, because graphical HTML editors can’t be expected to support our template language.
The syntax could be simplified by using an element as separator
rather than a container:<foo>
...
<bar/>
...
</foo>
However, this would go against the principle that elements are
containers rather than separators. According to [Empty], “——the
idea of using tags as separators between parts of
documents does not comply with the fundamental idea of SGML:
structured markup, or ‘generalized markup’ in the SGML
terminology. If a document consists of major parts A and
B, then adequate SGML markup is something like
<part>A</part><part>B</part>,
not A<divider>B.”
Since the template language is not a typical markup language and already makes heavy use of empty elements as place holders, it would probably have been a good idea to break the rules in order to make the syntax less verbose and to use a separator element.
Lasso’s LDML uses the separator syntax:[If ...]
...
[Else]
...
[/If]
Even though LDML is not an XML-based language but a programming language masquerading as a markup language, LDML can still be observed for gaining insight into the suitability of HTML-inspired syntax for use as a programming language syntax. Latest versions of Lasso support a language called LassoScript in addition to LDML. LassoScript removes the square brackets of LDML in order to make the syntax less markup-like [LassoVsPHP]. Assuming LassoScript was introduced in response to customer requests or customer defections to PHP, the introduction of LassoScript can be taken as an indication that markup language syntax is ill-suited as a programming language syntax.
Also, the compact syntax [RNG-CS] of RELAX NG [RNG] is a striking demonstration of how writability can be improved with a departure from the XML syntax when the XML syntax consists mainly of tags.
The verbosity of our template language when it comes to establishing a document context is not conclusive evidence about the suitability of the XML syntax for human-writable template languages. However, the verbosity of some aspects of our template language suggests that at least special care should be taken when designing such languages and that we probably weren’t quite careful enough.
The failure to enforce XHTML-level constraints was expected, and implementing checks for high-level constraints wasn’t even attempted. Nonetheless, the failure to guarantee all-round correctness is somewhat disappointing.
Developing a template linter for checking whether the template is guaranteed to yield correct output (as long as the data source does not violate the API contract) would be an interesting problem. Also, it would be interesting to explore whether RELAX NG [RNG] could be used in such checking.
A solution for avoiding overlapping ID attributes would also be an eligible subject for further work. A solution to the problem could be applicable outside our Template Engine, as well.
As discussed above, the syntax establishing a document context is verbose. Writing templates would be more convenient if the syntax could be made less verbose. One possibility already outlined is using a separator element instead of container elements.
Another solution would be going back to non-XML templating syntaxes and developing a solution that, nonetheless, allows the use of the DOM and the enforcement of well-formedness. One possibility is making the template language part of the character data from the point of view of the XML processor. The character data reported by the XML processor could then be parsed in a SAX filter. Upon encountering pieces of the template syntax, the parser within the SAX filter could emit SAX events, so that the observable results at the next SAX pipeline stage would be the same as if the XML parser was parsing the template language of our current implementation.
Contrary to the usual text-based templating methods, this approach would genuinely involve writing the template language inside an XML document in a non-XML language as opposed to making it look that way but treating the pieces of markup as string literals in the syntax tree of the template language.
Even though the Unicode-orientedness of Java and XML wins us support for all characters that can be expressed on the Web, being able to pass through Unicode strings intact is not enough for some languages.
For successful layout of paragraphs consisting of mainly Hebrew or Arabic text, the dominating text direction of the paragraphs has to be declared right-to-left. In HTML and XHTML, the dominating text direction is declared using the dir attribute. [Direction]
Some browsers apply heuristics based on the character encoding of the document in order to choose optimal fonts for various language groups. Our Template Engine always produces UTF-8 output, so the heuristics based on the character encoding cannot be used. Instead, to improve the presentation, the heuristics can use language metadata from the lang attribute of HTML. (Mozilla, for example, works this way.) [Fonts]
In Unicode, the “same” ideographs from Chinese, Japanese and Korean (CJK) have been unified in some cases. Language metadata is used for choosing a suitable font for Simplified Chinese, Traditional Chinese, Japanese or Korean. Also, the presentation of Central European languages, such as Polish, that require characters which aren’t available in legacy fonts designed for the Western European market can be improved in some rendering environments by using heuristics tied to the language metadata. [Lang]
Language markup is discussed in length in [Kielimerkkaus].
The Template Engine fails to copy some language and directionality metadata when it copies content from a document tree to another. For monolingual sites, the language and directionality can be hard-coded in the template. However, in order to achieve maximal correctness and suitability for building multilingual sites, the Template Engine would have to be improved to preserve the language and directionality metadata.
Without a doubt, actual deployment will show needs for extending
the template language. One foreseeable area of improvement is making
all links to next and previous documents from documents that are part
of a larger ordered collection of documents. The improvements could
also include generation of HTML link elements [HTML4]
for navigating in document collections.
Unlike text-based templating packages, our Template Engine is successful in enforcing XML well-formedness and comparable HTML correctness. Enforcement of higher-level correctness was neither expected nor achieved. Still, the design of the template language makes it easy to write templates that produce correct output.
However, writing templates is not as easy as originally hoped, because some syntactic constructs grew more verbose than initially expected. Indeed, the templates have to be written by hand because mixing the template language with XHTML makes the template documents ill-suited for editing in graphical HTML editors.
Despite some problems, the DOM worked very well as the framework underneath the Template Engine. However, we think anticipating performance problems with the DOM and designing the Template Engine from the beginning to work with an explicitly invalidated cache was a good direction to take.
The native Unicode-orientedness of both Java and XML allows the system to support an immensely wide variety of languages compared to the Finnish baseline requirement of supporting Finnish, Swedish and English. Still, additional work is needed for thorough internationalization.
Although the Template Engine has not yet been deployed on a real site, we believe the template language, although very limited, is expressive enough for creating the kind of pages the system was envisioned to host (company news, lists of downloadable files, list of upcoming events, site-wide navigation wrapped around generic (X)HTML content). We also think the Template Engine is extensible enough (either by modifying the class itself or by subclassing it) to adapt to needs that and similar to those that were envisioned but were not addressed.
Since the Template Engine has been designed as a reusable component, it could be integrated to a system other than the one developed in this project. For example, it could be integrated into a personal Web publishing system.
<?xml version="1.0"?>
<html
xmlns="http://www.w3.org/1999/xhtml"
xmlns:t="http://aranea.fi/webcms"
>
<head>
<title><t:title/></title>
</head>
<body>
<t:body/>
</body>
</html>
<?xml version="1.0"?>
<html
xmlns="http://www.w3.org/1999/xhtml"
xmlns:t="http://aranea.fi/webcms"
xmlns:news="http://aranea.fi/webcms/news"
>
<head>
<title>News</title>
<link
href="/style.css" rel="stylesheet"
type="text/css"/>
</head>
<body>
<t:foreach>
<news:list
name="news" limit="7"/>
<t:found>
<h1>Latest
News</h1>
<t:item>
<h2><t:a><t:title/></t:a></h2>
<p><t:firstP/></p>
</t:item>
</t:found>
<t:notFound>
<h1>No
News</h1>
<p>Sorry.
There is no
news.</p>
</t:notFound>
</t:foreach>
</body>
</html>