I’ve been researching the problem area of bug 18333. That is, I have talked to gurus, read code, visualized the class structure and planned possible approaches.
Just a quick note to casual observers: A content sink is an object that sits between the parser and the content model (DOM tree) and gets data (tokenized on the markup level like start element, end element, etc.) from the parser and builds the content model (DOM tree). On the server side one usually talks about a SAX-to-DOM tree builder.
So what is wanted here? Basically, when an XML document (including XHTML, MathML and SVG) is loaded in the browser for rendering in the content area, we want the document to render incrementally if wall clock time indicates that building the content model (DOM) takes long enough for the duration to be noticed by a human.
However, the scenarios can be more complex. First, if the document references an XSLT transformation, the content sink must not give the source document to the layout engine. Instead, the content sink must build the source document without layout, hand the source doc to the XSLT engine and pass the transformation result to layout. Second, if an XML document has neither an CSS style sheet nor an XSLT transformation associated with it and none of the elements has a specialized DOM interface, the content sink kicks off the XML pretty-printer. If a chance of pretty-printing exists, the layout mustn’t start.
Also, the changes must not break XUL, XBL, RDF or XMLHttpRequest.
Then there’s even a content sink for XML fragments. That looks
suspicious. It appears to be used for innerHTML in the
XHTML context.
Finally, since a fatal error can be encountered after the layout has been kicked off, something needs to be done with error reporting. Tearing down the document in mid-layout and replacing it with the Yellow Screen of Death would make the user experience unstable. I think the right way to address the problem is to show an error banner similar to the missing plug-in banner.
So in the cognitive style of PowerPoint:
Use a banner for error reporting.
Don’t be incremental with XSLT.
Don’t be incremental if pretty-printing might still happen.
Don’t be incremental with innerHTML.
Don’t be incremental with XHR.
Don’t be incremental with DOM LS.
Don’t be incremental with XUL—at least not when loading the local UI.
Don’t be incremental with XBL when loading a binding.
Don’t be incremental with RDF when loading a graph.
Otherwise, be incremental.
The HTML content sink is already incremental and has been for
years. It builds the content model using Gecko’s internal
nsIContent family of interfaces rather than the public
DOM interfaces. With the internal interfaces, adding nodes to the
content model and notifying observers that nodes have been added are
two different operations. The HTML content sink adds nodes to the
tree straight away when it gets a token from the parser, but the
notifications are deferred.
The actual tree building code is mostly in an inner class called
SinkContext to which the content sink delegates. This
makes the code unamenable to subclassing. Sink contexts implement
what conceptually is more or less the same idea as the insertion mode
in the HTML5 parsing spec.
The main part of incremental flushing lives in HTMLContentSink
itself. There are two timers. One timer is used to measure the time
the calls to the content sink take. That is, the timer is used to
sample the clock—not to fire a callback. The other timer fires a
callback. The first timer is used to cause flushes as side effects to
calls to the content sink. My guess is that the point of the second
timer that fires on its own is to make sure that flushing happens
even if the network stalls and there are no incoming parser tokens
for a while.
Since Gecko runs the parser, content sink and layout on the UI thread, there’s an interesting leaky abstraction in the content sink (quoting the comments):
There is both a high frequency interrupt mode and a low frequency interrupt mode controlled by the flag
NS_SINK_FLAG_DYNAMIC_LOWER_VALUEThe high frequency mode interrupts the parser frequently to provide UI responsiveness at the expense of page load time. The low frequency mode interrupts the parser and samples the system clock infrequently to provide fast page load time. When the user moves the mouse, clicks or types the mode switches to the high frequency interrupt mode. If the user stops moving the mouse or typing for a duration of time (mDynamicIntervalSwitchThreshold) it switches to low frequency interrupt mode.
The code that handles this stuff liven in HTMLContentSink
itself and, therefore, could be hoisted to a superclass. However, the
methods involved are not the token handling methods themselves but in
methods that get called before and after the methods that process the
tokens. The XML content sink does not use such pre/post-methods at
all right now.
I discussed this with gurus both via email and face to face at
XTech. The clear consensus was that I should hoist the incrementality
handling code to a common superclass of HTMLContentSink
and nsXMLContentSink.
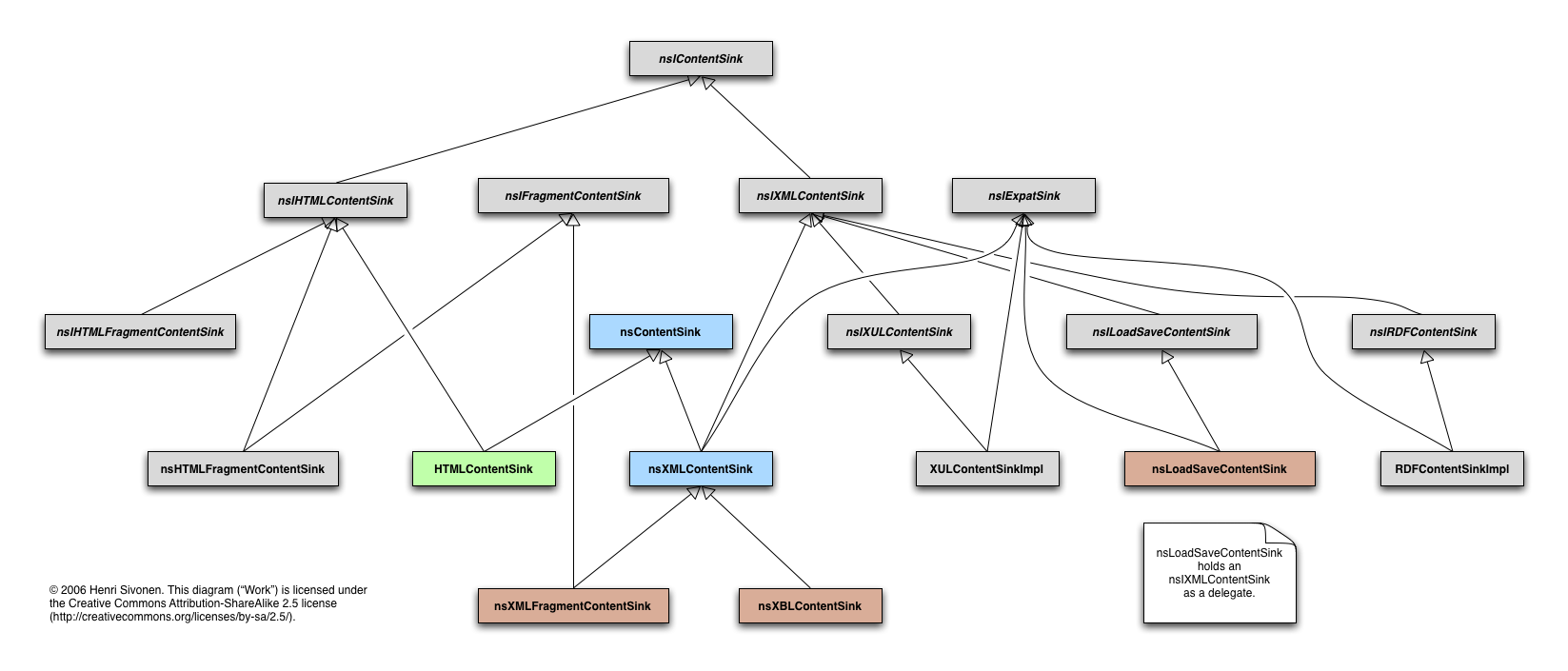
I mapped the class structure and discovered that my preconceptions about it were wrong. For example, I thought XBL was handled similarly to XUL separately from generic XML. It is not. The XUL content sink does not inherit from the generic XML content sink but the XBL content sink does.
Vector graphics with hyperlinks to LXR (PDF, 48 KB)
Bitmap without hyperlinks (PNG, 100 KB)
Source (OmniGraffle 4.1.1, 88 KB)
The green box (HTMLContentSink) has the incrementality
code. The blue boxes (nsContentSink and
nsXMLContentSink) are the ones that should be refactored
to get stuff that is now only in the green box. The red boxes
(nsXMLFragmentContentSink, nsXBLContentSink
and nsLoadSaveContentSink) are in danger of getting
adverse fallout of the refactoring.
I think there needs to be a flag for turning all the new code off.
This flag should be set if XSLT is involved, if the code is called
from XHR or DOM LS or if we are actually in an instance of a subclass
of nsXMLContentSink.
Then I should hoist all the methods dealing with incrementality
management and their related fields form HTMLContentSink
to nsContentSink. The code that actually does the
content model flushes should probably be left in the subclasses and
be called as abstract methods in nsContentSink.
All the flushes on the XML side need to check if it is (from the pretty-printing point of view) safe to be incremental and only start flushing once it is certain that pretty-printing won’t happen.
I’d rather not factor anything out of SinkContext.
I don’t want to revamp the HTML side right now. I think it would be
great to have an HTML5-compliant fresh reimplementation of both the
HTML parser and the sink, but I’m supposed to focus on the XML
side.
I should also figure out how to show an error banner and get rid of the Yellow Screen of Death.
Does this look right? I’d appreciate feedback in mozilla.dev.tech.xml.
{kind=link}